声明:本文来自于微信公众号 新智元(ID:AI_era),作者:新智元,授权站长之家转载发布。
近日,LLM竞技场更新了战报,Command R+推出不到一周,就成了历史上第一个击败了GPT-4的开源模型!目前,Command R+已经上线HuggingChat,可以免费试玩。
GPT-4又又又被超越了!
近日,LLM竞技场更新了战报,人们震惊地发现:居然有一个开源模型干掉了GPT-4!
这就是Cohere在一周多前才发布的Command R+。

排行榜地址:https://huggingface.co/spaces/lmsys/chatbot-arena-leaderboard
截至小编码字的这个时间,竞技场排行榜更新到了4月11号,Command R+拿到了2.3万的投票,
综合得分超越了早期版本的GPT-4(0613),和GPT-4-0314版本并列第7位,——而它可是一个开源模型(不允许商用)。

这边建议Altman,不管是GPT-4.5还是GPT-5,赶紧端上来吧,不然家都被偷没了。
不过事实上OpenAI也没闲着,在被Claude3一家屠榜,忍受了短暂的屈辱之后,很快就放出了一个新版本(GPT-4-Turbo-2024-04-09),直接重归王座。
这也导致排行榜上大家的排名瞬间都掉了一位,本来Command R+在9号的版本中是排位全球第6的。
——大哥你不讲武德!

尽管如此,Command R+作为首个击败了GPT-4的开源模型,也算是让开源社区扬眉吐气了一把,而且这可是大佬认可的堂堂正正的对决。

Cohere的机器学习总监Nils Reimers还表示,这还不是Command R+的真实实力,它的优势区间是RAG和工具使用的能力,而这些外挂能力在LLM竞技场中没有用到。

事实上,在Cohere官方将Command R+描述为「RAG优化模型」。
「割麦子」和最大的开源模型
毫无疑问,Cohere是当前AI领域的独角兽,而它的联合创始人兼CEO,正是大名鼎鼎的「Transformer八子」之一的「割麦子」(Aidan Gomez)。

作为Transformer最年轻的作者,一出手就是最大规模的开源模型:

正面对战claude-3, mistral-large, gpt-4turbo;
1040亿参数;
使用多步骤工具和RAG构建;
支持10种语言;
上下文长度为128K;
基于上下文的引用和响应;
针对代码能力进行了优化;
提供4位和8位的量化版本。
Command R+专为实际企业用例而构建,专注于平衡高效率和高精度,使企业能够超越概念验证,并通过AI进入生产。

huggingface地址:https://huggingface.co/CohereForAI/c4ai-command-r-plus
量化版本:https://huggingface.co/CohereForAI/c4ai-command-r-plus-4bit
——当然了,1040亿的参数量,相比于前段时间Musk开源的Grok-1(3140亿)还差了一些,但Command R+并非Grok那种MoE架构,
所以这1040亿参数是实打实的完全用于推理,而Grok-1的活跃参数为860亿——从这个角度来看,说Command R+是目前规模最庞大的开源模型也不为过。
作为Command R的进化版本,进一步全面提高了性能。主要优势包括:
-高级检索增强生成(RAG)与引用以减少幻觉
-10种主要语言的多语言覆盖,支持全球业务运营
-工具的运用以自动化复杂的业务流程
在性能优于竞品的同时,Command R+还提供了相对低得多的价格。
目前,Cohere已经与多家大厂合作,并将LLM部署到了Amazon Sagemaker和Microsoft Azure。

上面左图展示了Azure上可用的模型,在三个关键功能方面的性能比较(模型在基准测试中的平均得分):多语言、RAG和工具使用。
右图比较了Azure上可用模型的每百万个输入和输出token成本。
行业领先的RAG解决方案
企业想通过专有数据定制自己的LLM,就必然绕不开RAG。
Command R+针对高级RAG进行了优化,可提供高度可靠、可验证的解决方案。
新模型提高了响应的准确性,并提供了减轻幻觉的内联引用,可帮助企业使用AI进行扩展,以快速找到最相关的信息,
支持跨财务、人力资源、销售、营销和客户支持等业务职能部门的任务。

上面左图是在人类偏好上的评估比较结果,包括文本流畅度、引文质量和整体效用,其中引文是在连接到源文档块的摘要上衡量的。
这里使用了250个高度多样化的文档和摘要请求的专有测试集,包含类似于API数据的复杂指令。基线模型经过了广泛的提示设计,而 Command R+使用RAG-API。
右图衡量了由各种模型提供支持的多跳REACT代理的准确性,可以访问从维基百科(HotpotQA)和互联网(Bamboogle、StrategyQA) 检索的相同搜索工具。
HotpotQA和Bamboogle的准确性由提示评估者(Command R、GPT3.5和Claude3-Haiku)的三方多数投票来判断, 以减少已知的模型内偏差。
这里使用人工注释对一千个示例子集进行了验证。StrategyQA的准确性是使用以是/否判断结尾的长格式答案来判断的。
使用工具自动执行复杂流程
作为大语言模型,除了摄取和生成文本的能力,还应该能够充当核心推理引擎:能够做出决策并使用工具来自动化需要智能才能解决的困难任务。
为了提供这种能力,Command R+提供了工具使用功能,可通过API和LangChain访问,以无缝地自动化复杂的业务工作流程。
企业用例包括:自动更新客户关系管理(CRM)任务、活动和记录。
Command R+还支持多步骤工具使用,它允许模型在多个步骤中组合多个工具来完成困难的任务,——甚至可以在尝试使用工具并失败时进行自我纠正,以提高成功率。

上图为使用Microsoft的ToolTalk(Hard)基准测试,和伯克利的函数调用排行榜(BFCL)评估对话工具使用和单轮函数调用功能。
对于ToolTalk,预测的工具调用是根据基本事实进行评估的,总体对话成功指标取决于模型召回所有工具调用和避免不良操作(即具有不良副作用的工具调用)的可能性。
对于BFCL,这里使用了2024年3月的版本,在评估中包含了错误修复,并报告了可执行子类别的平均函数成功率得分。通过额外的人工评估清理步骤验证了错误修复,以防止误报。
多语言支持
Command R+在全球业务的10种关键语言中表现出色:中文、英语、法语、西班牙语、意大利语、德语、葡萄牙语、日语、韩语、阿拉伯语。

上图为FLoRES(法语、西班牙语、意大利语、德语、葡萄牙语、日语、韩语、阿拉伯语和中文)以及WMT23(德语、日语和中文)翻译任务的模型比较。
此外,Command R+还具有一个优秀的分词器,可以比市场上其他模型使用的分词器更好地压缩非英语文本,能够实现高达57%的成本降低。

上图比较了Cohere、Mistral和OpenAI分词器为不同语言生成的token数量。
Cohere分词器生成的表示相同文本的token要少得多,尤其在非拉丁文字语言上减少的幅度特别大。比如在日语中,OpenAI分词器输出的token数量是Cohere分词器的1.67倍。
价格

网友评价
Command R+的开源点燃了网友们的热情,网友表示:「GPT-4级性能,在家运行」。

不知道这3.15G的内存占用是什么情况?

「感谢Cohere做了Mistral没有做的事情」。

「根据我有限的初始测试,这是目前可用的最好的模型之一......而且它绝对有一种风格,感觉很好。感觉不像是ChatGPT主义的填充模型。」

——是时候为自己加一块显卡了!
上线HuggingChat
目前,Command R+已经上线HuggingChat(https://huggingface.co/chat),最强开源模型,大家赶快玩起来!

问:等红灯是在等红灯还是等绿灯?

解释一下咖啡因来自咖啡果:

请回答弱智吧问题:陨石为什么每次都能精准砸到陨石坑?

我想配个6000多的电脑,大概要多少钱?

HuggingFace联创Thomas Wolf曾表示,最近在LLM竞技场上的情况发生了巨大变化:

Anthropic 的Claude3家族成了闭源模型的赢家(曾经);而Cohere的Command R+是开源模型的新领导者。
2024年,在开源和闭源两条道路上,LLM都发展迅猛。
最后,放上两张LLM竞技场的当前战况:
模型A在所有非平局A与B战斗中获胜的比例:
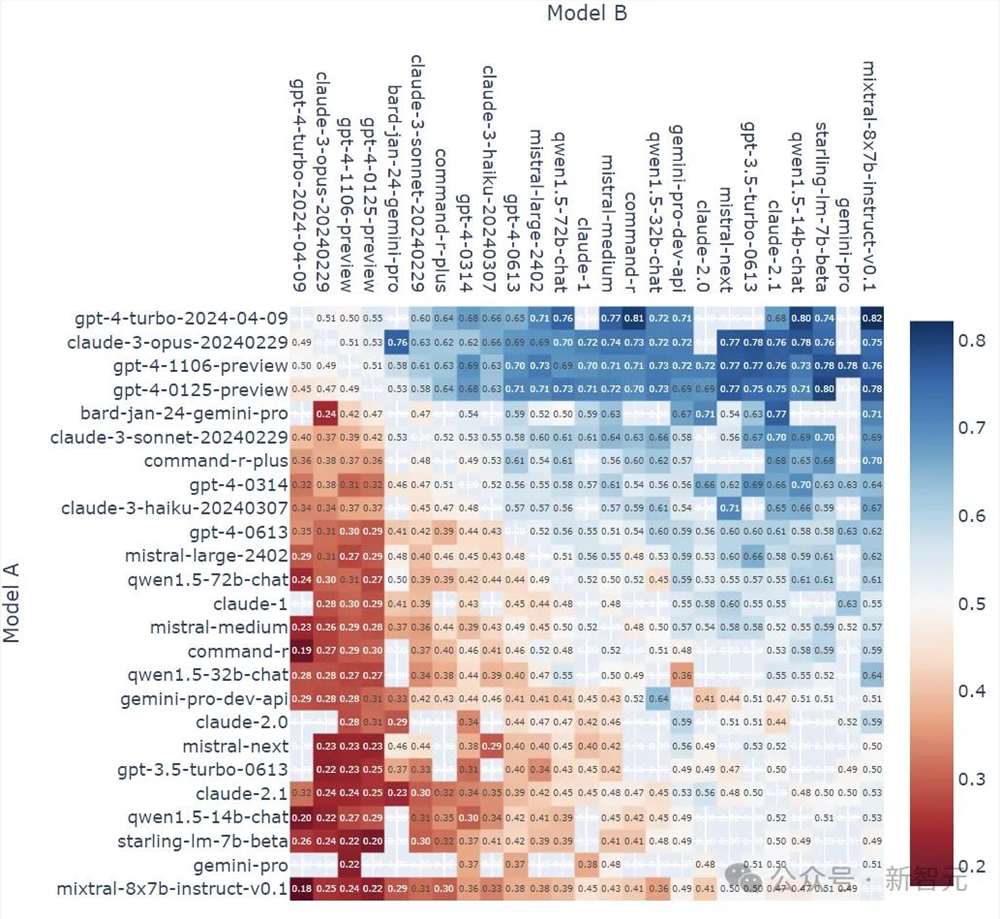
每种模型组合的战斗计数(无平局):

参考资料:
https://venturebeat.com/ai/coheres-command-r-now-available-on-huggingchat/
https://twitter.com/lmsysorg/status/1777630133798772766
 相关文章
相关文章



 头条焦点
头条焦点




 精彩导读
精彩导读 关注我们
关注我们
【查看完整讨论话题】 | 【用户登录】 | 【用户注册】