声明:本文来自于微信公众号 新智元(ID:AI_era),作者:新智元,授权站长之家转载发布。
【新智元导读】AI初创公司Reka最新推出的多模态语言模型Reka Core具备理解图像、音频和视频等多种模式数据内容的惊人能力,是继谷歌的Gemini Ultra之后的又一个令人瞩目的作品,性能上与GPT-4不相上下!
多模态语言模型又双叒叕上新了!
近日,由DeepMind、谷歌和Meta的研究人员创立的AI初创公司Reka,推出了他们最新的多模态语言模型——Reka Core。
它被誉为该公司「最大、最有能力」的模型,在性能上与GPT-4和Claude3Opus不相上下!
Reka的首席科学家兼联合创始人Yi Tay兴奋地表示,过去几个月,该公司使用了「数千台H100」来开发Reka Core。

能够达到GPT-4或Opus的水平是研究团队中许多人的目标。
从头开始训练模型来与OpenAI的GPT-4和Claude3Opus相媲美无疑是一项壮举。
目前Core仍在改进,在后续的时间里,兴许会有更多有趣的内容陆续推出!
对于这个新推出的模型,网友们叫好声一片~


还有网友看了官方发布的视频后惊叹:这莫不就是传说中的AGI,有点迫不及待了!!!

Core是Reka语言模型系列中的第三个成员,由多个来源训练而成,包括公开数据、授权数据以及涵盖文本、音频、视频和图像文件的合成数据。

它能够理解图像、音频和视频等多种模式的数据内容。

最重要的是,尽管只用了不到一年的时间就完成了训练,但它的性能却可以媲美或超越人工智能领域领先的顶级模型。
虽然Reka Core的确切参数数量尚未披露,但该公司首席执行官Dani Yogatama认为它是一个「非常庞大的模型」(上一个模型Reka Flash有210亿个参数)。
Core还支持32种语言和128,000个词组的上下文窗口,这也就让该模型在处理长篇文档方面具备了极强的优势。
可以说,Core是继谷歌的Gemini Ultra之后第二个涵盖从文本到视频等所有数据模式并且能够提供高质量输出的模型了。
此外,Yogatama还表示,研究团队正在训练Core以进一步提高其性能,同时也在开发下一个版本,并且表示该公司没有开源该技术的计划。
技术细节
训练数据
训练数据由公开可用和专有/许可数据集组成,其中包括包括文本、图像、视频和音频剪辑,获取数据的截止日期为2023年11月。
虽然并未对语料库的内容进行严格意义上的分类,但预训练数据中大约25%的数据是与代码相关的,30%的数据是与STEM相关。
其中约有25%的数据是网络爬取获得的并且约10%的数据跟数学相关。
总体混合率一般遵循优先考虑独特标记的原则,但会根据数量有限的小规模消融产生的信号进行人工调整

预训练数据中大约15%是明确的多语言数据,由32种不同的语言按分层加权组成。
除了这些明确加权的语言之外,为了让大多数语言都有基准性能,研究团队还在包含110种语言的维基百科上进行训练。
模型架构
Reka模型架构是一个模块化的编码器-解码器架构,支持文本、图像、视频 和音频输入。目前,我们的模型仅支持文本输出。

模型主要使用Pytorch在Nvidia H100上进行训练。

研究团队表示,尽管训练过程学习率非常高,但损失峰值很少,因此模型预训练过程相对比较顺利。
后训练(Post-Training)
经过预训练后,模型使用强正则化技术对多个epoch进行指令调整。
对于SFT,研究团队使用混合数据集进行训练,其中包括他们的专有数据和公开数据。
SFT之后,使用RLHF方法进行对齐。
此外,在后训练过程中,研究人员还考虑了工具使用、函数调用和网络搜索等内容。
性能亮点
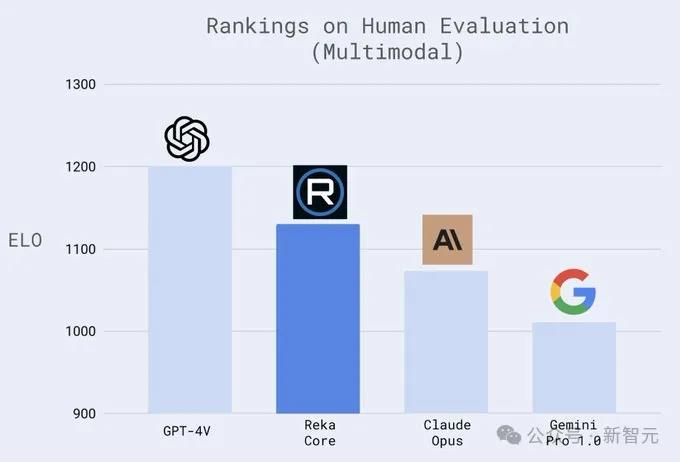
在业界公认的关键评估指标方面,Core与OpenAI、Anthropic和谷歌的模型相比具有很强的竞争力。
考虑到它的模型大小和性能,从总体成本的角度来看,Core能带来巨大的价值。

Core拥有强大功能的同时,部署也十分灵活,由此开启了大量新的应用案例。
在视频感知测试中,Core的表现远远超过其唯一的竞争对手Gemini Ultra(59.3分对54.7分)。
同时,在针对图像任务的MMMU基准测试中,Core以56.3的得分紧随GPT-4(56.8)、Claude3Opus(59.4)、Gemini Ultra(59.4)和 Gemini Pro1.5(58.5)之后。
即使在其他基准测试中,Core也能媲美行业领先模型。
例如,在知识任务的MMLU测试中,它获得了83.2分,紧随GPT-4、Claude3Opus和Gemini Ultra之后。
在推理的GSM8K基准测试和编码的HumanEval测试中,它分别以92.2分和76.8分击败了GPT-4。
下表总结了Core与目前市场上领先模型的比较。

模型能力
1. 多模态(图像和视频)理解
Core 不仅仅是一个前沿的大型语言模型,它对图像、视频和音频具有强大的上下文理解能力,是仅有的两个商用综合多模态解决方案之一。
2.128K上下文窗口
Core能够摄取并精确准确地调用更多信息。
3. 推理能力
Core在语言或者数学方面具有出色的推理能力,使其适用于需要精密分析的复杂任务。
4. 编码和代理工作流
Core是顶级代码生成器。它的编码能力与其他功能相结合时,可以增强代理工作流程的能力。
5. 支持多种语言
Core是在32种语言的文本数据上进行的预训练,因此,它能说流利的英语以及好几种亚洲和欧洲的语言。
6. 部署灵活性
与Reka其他型号的模型(Flash和Edge)一样,Core可通过API、本地或设备部署,以满足客户和合作伙伴的部署限制。
参考资料:
https://venturebeat.com/ai/reka-releases-reka-core-its-multimodal-language-model-to-rival-gpt-4-and-claude-3-opus/
https://x.com/YiTayML/status/1779895037335343521https://x.com/artetxem/status/1779895714438365284
 相关文章
相关文章

 头条焦点
头条焦点




 精彩导读
精彩导读 关注我们
关注我们
【查看完整讨论话题】 | 【用户登录】 | 【用户注册】