声明:本文来自于微信公众号硅星GenAI(ID:gh_e06235300f0d),作者:苗正,授权站长之家转载发布。
相信你或多或少对GPT有一定的了解,但我赌你没听说过bGPT。bGPT的意思是byte GPT,即字节GPT。这是一种专门设计用于处理二进制数据和模拟数字世界的深度学习模型。简单概括,bGPT突破了传统语言模型的局限,能够直接理解和操作二进制数据,拓展了深度学习在原生二进制数据领域的应用边界。
bGPT的成果来自于微软亚洲研究院、清华大学以及中央音乐学院的共同开发,等会你就知道这里为什么会有中央音乐学院了,希望你还没有忘记五线谱。

从运行逻辑来看,bGPT反而很像是在解数学题
在硅星人Pro的文章《揭秘Sora:用大语言模型的方法理解视频,实现了对物理世界的“涌现”》中提到,大语言模型有一个核心功能是通过代码将多种文本形式进行了统一。正是这种数据结构上的相同,才让大语言模型实现“思考”,进而生成各种各样的内容。但是文字的数据结构和音频、图像、符号、CPU状态数据等等完全不相同,所以想要只使用一个大模型就完成对所有类型数据结构的学习,并不容易。
不过我们每一个使用电子产品的人都清楚,无论是何种类型的数据,它是由“字节”组成的。因此,研究团队提出了一个想法,是否能用字节来代替传统的token,使得大模型可以把所有类型的数据放在一起进行训练推理。bGPT的技术原理是基于深度学习中的序列建模思想,通过训练模型对连续的字节序列进行预测,以理解并生成符合特定上下文的二进制数据。

bGPT可以处理不同类型的声音文件
如果说transformer模型的核心机制是自注意力,那么bGPT的核心机制就是“猜”。通过深度学习训练,学会根据当前字节序列预测接下来可能出现的字节,从而对数字世界的内在规律进行建模。即采用“下一个字节预测”的方式来模拟数字世界的各种活动。
就像大语言模型的预处理环节一样,bGPT也有预处理,而且逻辑上和大语言模型是一致的,也是将不同类型的数据(音频和图像)标准化为适合模型输入的格式。比如音频就会被转换为统一的WAV格式,设定采样率为8kHz,单声道,8位深度,并裁剪至一秒长度;而图像数据则被设置为32×32像素、RGB颜色模式、24位深度的BMP格式。
接下来模型使用最终解码层的补丁级特征,通过平均池化操作提取全局特征以供分类任务使用。这一步的作用是提取特征,为下一步的生成式建模做准备。为了凸显bGPT和市面上流传的文字、图像、视频大模型不同,研究团队特地选择了音乐作为模型生成的内容。

论文所选取的乐谱
论文使用了两种文件类型来做演示,第一种是ABC记谱法,第二种是MIDI。ABC记谱法是一种简洁的人工编写的文本格式,用来描述音乐曲目,而MIDI是一种二进制格式,记录的是音乐演奏的具体表现细节。更直白一点,ABC记谱法就是我们人类看的操作手册,MIDI则是机器用模拟环境来还原这份操作手册。
bGPT首先将成对的ABC记谱法文件和对应的MIDI文件合并成连续的字节序列,并用特殊的分割符标识两个文件之间的界限。接着,模型运用生成式建模的方法来学习这些字节序列的规律,从而实现了双向转换。也就是说,bGPT可以将基于文本的ABC记谱法乐谱转换为MIDI二进制表演信号,以及将MIDI文件还原回ABC记谱法文本格式。
在实际效果上,bGPT在完成这项任务时展现了非常高的精确度。研究团队在论文中写到,在将ABC记谱法转换为MIDI格式时,错误率低至每字节仅0.0011比特。尽管转换过程中可能会遇到一些挑战,比如MIDI转回ABC时,由于MIDI不支持重复符号,导致ABC乐谱在视觉上显得比原始版本更为冗长,装饰音符也可能因MIDI的表现方式而在转换回ABC时无法完全精确对应,但总体上bGPT成功地模拟了这个数据转换的过程,证明了它在模拟和处理数字世界中不同数据格式间转换的能力。
此外,为了评估bGPT在模拟数字过程方面的性能,研究人员还创建了一个CPU状态数据集,通过Python脚本模拟CPU的操作,让bGPT学习和预测CPU执行不同指令时的状态变化,结果显示bGPT在此类硬件行为模拟上的准确性超过99.99%,进一步验证了其在模拟数字世界复杂过程的有效性和潜力。
所谓CPU状态集,是一个专为评估和训练bGPT模型而构建的合成数据集,它模拟了CPU在执行一系列机器指令后内部寄存器状态的变化情况。此数据集中每个实例都包含了1KB大小的内存块,其中包含一定数量的机器指令,随后是一系列16字节的CPU寄存器状态序列,反映了每次执行指令后CPU的最新状态。寄存器主要包括了程序计数器、累加器、指令寄存器、通用寄存器。
那么换句话说,这CPU状态集,其实就是想让bGPT来模仿CPU的物理运行逻辑。研究团队之所以选择这种类型的数据结构,就是为了和传统大模型进行区分。人家玩的就是时髦,玩的就是另类。
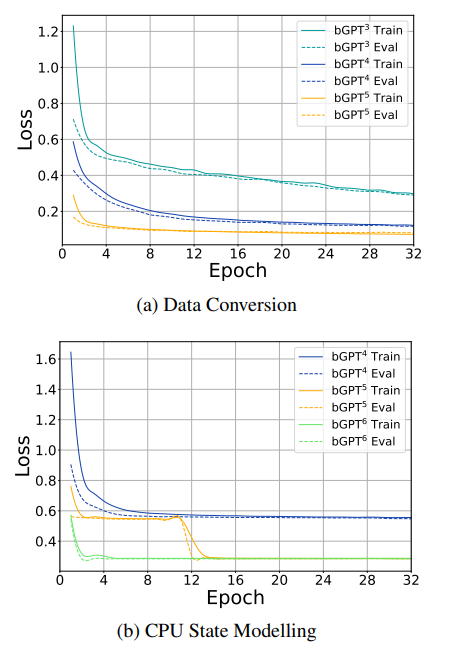
损失函数和周期的关系图
让我们看这两张图,上面的是ABC记谱法/MIDI所对应的数据转换任务,下面就是CPU状态建模任务。Loss代表损失函数(loss function),Epoch代表完整周期。随着epoch数的增加,模型会不断更新权重参数,以期在后续的Epoch中达到更低的损失水平。结果证明,模型预测输出越来越接近实际标签,拟合程度越来越好,预测能力越来越强。
数据转换任务使用IrishMAN数据集进行验证,不是我吹牛,这个数据集一般研究大模型的都不一定认识。它是一个包含了20多万首爱尔兰乐谱的ABC记谱法数据集。其中99%(214122首曲子)用于训练,1%(2162首曲子)用于验证。为了确保格式的统一,所有曲调都被转换为XML,然后使用脚本转换回ABC记谱法,并且包含自然语言的字段(例如,标题和歌词)被删除。

IrishMAN数据集
bGPT是非常有创意的,因为字节是最基本的信息存储单位,而且虽然人类用肉眼可能没办法理解0和1,但是不同类型的文件,它所对应的字节是截然不同的。咱们就拿音乐来说,它的字节是音频数据、编码格式、元数据。音频数据是声音振幅和频率随时间的变化,编码格式是表示方法(MP3、WAV等),元数据是这段声音的信息(歌曲名称、表演者、所属专辑等)。
因此这些字节是有规律可循的,它具备明显的特征,只不过人类识别不了罢了。借由当下火热的大模型技术,对这种格式的数据结构进行处理,最后成功实现。以这个逻辑来发展,是有可能发展出性能更强大的模型的。bGPT为这条道路开了个好头。
 相关文章
相关文章 头条焦点
头条焦点




 精彩导读
精彩导读 关注我们
关注我们
【查看完整讨论话题】 | 【用户登录】 | 【用户注册】