声明:本文来自于微信公众号 机器之心(ID:almosthuman2014),作者:机器之心,授权站长之家转载发布。
AI 视频生成,是最近最热门的领域之一。各个高校实验室、互联网巨头 AI Lab、创业公司纷纷加入了 AI 视频生成的赛道。Pika、Gen-2、Show-1、VideoCrafter、ModelScope、SEINE、LaVie、VideoLDM 等视频生成模型的发布,更是让人眼前一亮。v⁽ⁱ⁾
大家肯定对以下几个问题感到好奇:
到底哪个视频生成模型最牛?
每个模型有什么特长?
AI 视频生成领域目前还有哪些值得关注的问题待解决?
为此,我们推出了 VBench,一个全面的「视频生成模型的评测框架」,来告诉你 「视频模型哪家强,各家模型强在哪」。

论文:https://arxiv.org/abs/2311.17982
代码:https://github.com/Vchitect/VBench
网页:https://vchitect.github.io/VBench-project/
论文标题:VBench: Comprehensive Benchmark Suite for Video Generative Models
VBench 不光能全面、细致地评估视频生成的效果,而且还特别符合人们的感官体验,能省下一大堆评估的时间和精力。
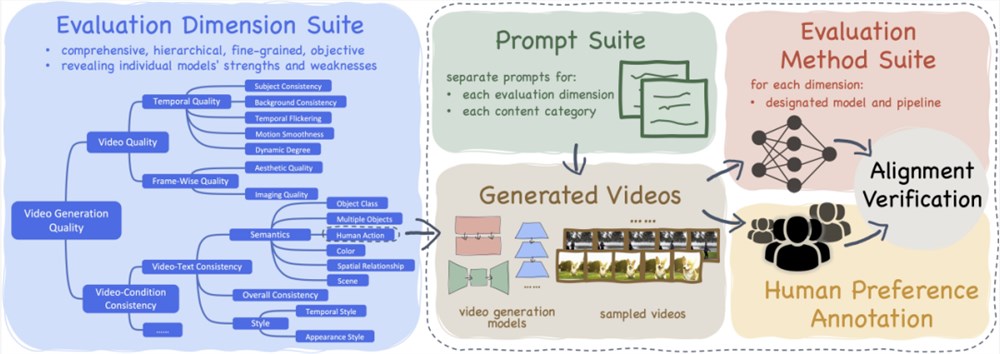
VBench 包含16个分层和解耦的评测维度
VBench 开源了用于文生视频生成评测的 Prompt List 体系
VBench 每个维度的评测方案与人类的观感与评价对齐
VBench 提供了多视角的洞察,助力未来对于 AI 视频生成的探索
AI 视频生成模型 - 评测结果
已开源的 AI 视频生成模型
各个开源的 AI 视频生成模型在VBench 上的表现如下。

各家已开源的 AI 视频生成模型在 VBench 上的表现。在雷达图中,为了更清晰地可视化比较,我们将每个维度的评测结果归一化到了0.3与0.8之间。

各家已开源的 AI 视频生成模型在 VBench 上的表现。
在以上6个模型中,可以看到 VideoCrafter-1.0和 Show-1在大多数维度都有相对优势。
创业公司的视频生成模型
VBench 目前给出了 Gen-2和 Pika 这两家创业公司模型的评测结果。

Gen-2和 Pika 在 VBench 上的表现。在雷达图中,为了更清晰地可视化比较,我们加入了 VideoCrafter-1.0和 Show-1作为参考,同时将每个维度的评测结果归一化到了0.3与0.8之间。

Gen-2和 Pika 在 VBench 上的表现。我们加入了 VideoCrafter-1.0和 Show-1的数值结果作为参考。
可以看到,Gen-2和 Pika 在视频质量(Video Quality)上有明显优势,例如时序一致性(Temporal Consistency)和单帧质量(Aesthetic Quality 和 Imaging Quality)相关维度。在与用户输入的 prompt 的语义一致性上(例如 Human Action 和 Appearance Style),部分维度开源模型会更胜一筹。
视频生成模型 VS 图片生成模型
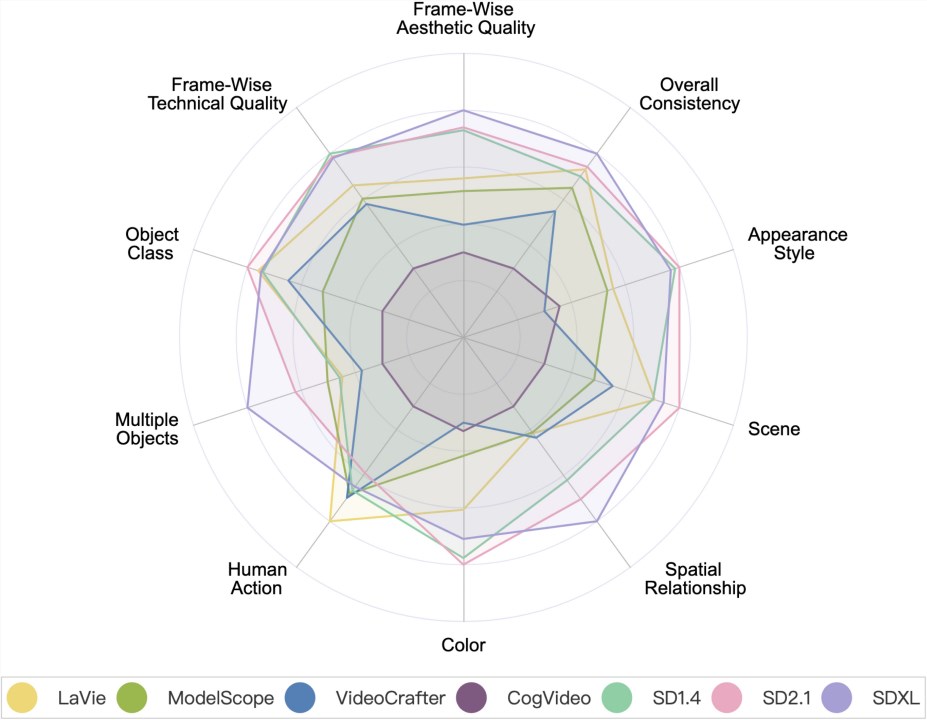
视频生成模型 VS 图片生成模型。其中 SD1.4,SD2.1和 SDXL 是图片生成模型。
视频生成模型在8大场景类别上的表现
下面是不同模型在8个不同类别上的评测结果。

VBench 现已开源,一键即可安装
目前,VBench 已全面开源,且支持一键安装。欢迎大家来玩,测试一下感兴趣的模型,一起推动视频生成社区的发展。



开源地址:https://github.com/Vchitect/VBench
我们也开源了一系列 Prompt List:https://github.com/Vchitect/VBench/tree/master/prompts,包含在不同能力维度上用于评测的 Benchmark,以及在不同场景内容上的评测 Benchmark。

左边词云展示了我们 Prompt Suites 的高频词分布,右图展示了不同维度和类别的 prompt 数量统计。
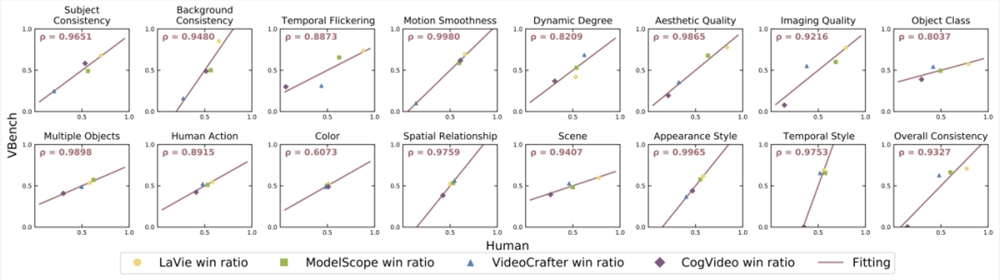
VBench 准不准?
针对每个维度,我们计算了 VBench 评测结果与人工评测结果之间的相关度,进而验证我们方法与人类观感的一致性。下图中,横轴代表不同维度的人工评测结果,纵轴则展示了 VBench 方法自动评测的结果,可以看到我们方法在各个维度都与人类感知高度对齐。
VBench 带给 AI 视频生成的思考
VBench 不仅可以对现有模型进行评测,更重要的是,还可以发现不同模型中可能存在的各种问题,为未来 AI 视频生成的发展提供有价值的 insights。
「时序连贯性」以及「视频的动态程度」:不要二选一,而应同时提升
我们发现时序连贯性(例如 Subject Consistency、Background Consistency、Motion Smoothness)与视频中运动的幅度(Dynamic Degree)之间有一定的权衡关系。比如说,Show-1和 VideoCrafter-1.0在背景一致性和动作流畅度方面表现很好,但在动态程度方面得分较低;这可能是因为生成「没有动起来」的画面更容易显得 「在时序上很连贯」。另一方面,VideoCrafter-0.9在与时序一致性的维度上弱一些,但在 Dynamic Degree 上得分很高。
这说明,同时做好 「时序连贯性」和 「较高的动态程度」确实挺难的;未来不应只关注其中一方面的提升,而应该同时提升 「时序连贯性」以及 「视频的动态程度」这两方面,这才是有意义的。
分场景内容进行评测,发掘各家模型潜力
有些模型在不同类别上表现出的性能存在较大差异,比如在美学质量(Aesthetic Quality)上,CogVideo 在 「Food」类别上表现不错,而在 「LifeStyle」类别得分较低。如果通过训练数据的调整,CogVideo 在 「LifeStyle」这些类别上的美学质量是否可以提升上去,进而提升模型整体的视频美学质量?
这也告诉我们,在评估视频生成模型时,需要考虑模型在不同类别或主题下的表现,挖掘模型在某个能力维度的上限,进而针对性地提升 「拖后腿」的场景类别。
有复杂运动的类别:时空表现都不佳
在空间上复杂度高的类别,在美学质量维度得分都比较低。例如,「LifeStyle」类别对复杂元素在空间中的布局有比较高的要求,「Human」类别由于铰链式结构的生成带来了挑战。
对于时序复杂的类别,比如 「Human」类别通常涉及复杂的动作、「Vehicle」类别会经常出现较快的移动,它们在所有测试的维度上得分都相对较低。这表明当前模型在处理时序建模方面仍然存在一定的不足,时序上的建模局限可能会导致空间上的模糊与扭曲,从而导致视频在时间和空间上的质量都不理想。
难生成的类别:提升数据量收益不大
我们对常用的视频数据集 WebVid-10M 进行了统计,发现其中约有26% 的数据与 「Human」有关,在我们统计的八个类别中占比最高。然而,在评估结果中,「Human」类别却是八个类别中表现最差的之一。
这说明对于 「Human」这样复杂的类别,仅仅增加数据量可能不会对性能带来显著的改善。一种潜在的方法是通过引入 「Human」相关的先验知识或控制,比如 Skeletons 等,来指导模型的学习。
百万量级的数据集:提升数据质量优先于数据量
「Food」类别虽然在 WebVid-10M 中仅占据11%,但在评测中几乎总是拥有最高的美学质量分数。于是我们进一步分析了 WebVid-10M 数据集不同类别内容的美学质量表现,发现 「Food」 类别在 WebVid-10M 中也有最高的美学评分。
这意味着,在百万量级数据的基础上,筛选 / 提升数据质量比增加数据量更有帮助。
待提升的能力:准确生成生成多物体,以及物体间的关系
当前的视频生成模型在 「多对象生成」(Multiple Objects)和 「空间关系」(Spatial Relationship)方面还是追不上图片生成模型(尤其是 SDXL),这凸显了提升组合能力的重要性。所谓组合能力指的是模型在视频生成中是否能准确展示多个对象,及它们之间的空间及互动关系。
解决这一问题的潜在方法可能包括:
数据打标:构建视频数据集,提供对视频中多个物体的明确描述,以及物体间空间位置关系以及互动关系的描述。
在视频生成过程中添加中间模态 / 模块来辅助控制物体的组合和空间位置关系。
使用更好的文本编码器(Text Encoder)也会对模型的组合生成能力有比较大的影响。
曲线救国:将 T2V 做不好的 「物体组合」问题交给 T2I,通过 T2I+I2V 的方式来生成视频。这一做法针对其他很多视频生成中的问题或许也有效。
 相关文章
相关文章
 头条焦点
头条焦点




 精彩导读
精彩导读 关注我们
关注我们
【查看完整讨论话题】 | 【用户登录】 | 【用户注册】