声明:本文来自于微信公众号 机器之心(ID:almosthuman2014),作者:机器之心,授权站长之家转载发布。
最近,有人在社交媒体上发布了一张有关 GPT4.5更新的截图。图中内容显示,和 GPT 系列之前推出的模型相比,GPT4.5最大的惊喜可能就是处理3D 和视频的能力。至于3D 能力到底是指看得懂3D 图像,还是能输入3D 模型,目前只能靠猜。OpenAI CEO Sam Altman 随后否认了该截图的真实性,GPT4.5的具体能力依然是一个谜。不过,在众多研究中,确实已经有大模型实现了多个模态同时处理,甚至连视频、3D 模型也囊括了进来。
给你一首曲子的音频和一件乐器的3D 模型,然后问你这件乐器能否演奏出这首曲子。你可以通过听觉来辨认这首曲子的音色,看它是钢琴曲还是小提琴曲又或是来自吉他;同时用视觉识别那是件什么乐器。然后你就能得到问题的答案。但语言模型有能力办到这一点吗?

实际上,这个任务所需的能力名为跨模态推理,也是当今多模态大模型研究热潮中一个重要的研究主题。近日,宾夕法尼亚大学、Salesforce 研究院和斯坦福大学的一个研究团队给出了一个解决方案 X-InstructBLIP,能以较低的成本让语言模型掌握跨模态推理。
人类天生就会利用多种感官来解读周围环境并和制定决策。通过让人工智能体具备跨模态推理能力,我们可以促进系统的开发,让其能更全面地理解环境,从而能应对仅有单个模态导致难以辨别模式和执行推理的情况。这就催生了多模态语言模型(MLM),其可将大型语言模型(LLM)的出色能力迁移到静态视觉领域。
近期一些研究进展的目标是通过整合音频和视频来扩展 MLM 的推理能力,其用的方法要么是引入预训练的跨模态表征来在多个模态上训练基础模型,要么是训练一个投影模型来将多模态与 LLM 的表征空间对齐。这些方法虽然有效,但前者往往需要针对具体任务进行微调,而后者则需要在联合模态数据上微调模型,这样一来就需要很多数据收集和计算资源成本。
该研究团队提出的 X-InstructBLIP 是一个可扩展框架,让模型可以在学习单模态数据的同时不受预训练的跨模态嵌入空间或与解冻 LLM 参数相关的计算成本和潜在过拟合风险的限制。

论文地址:https://arxiv.org/pdf/2311.18799.pdf
GitHub 地址:https://github.com/salesforce/LAVIS/
X-InstructBLIP 无缝地整合了多种模态并且这些模态各自独立,从而不必再使用联合模态数据集,同时还能保留执行跨模态任务的能力。
据介绍,这种方法使用了 Q-Former 模块,使用来自 BLIP-2的图像 - 文本预训练权重进行了初始化,并在单模态数据集上进行了微调以将来自不同模态嵌入空间的输入映射到一个冻结的 LLM。
由于某些模态缺乏指令微调数据,该团队又提出了一个简单又有效的方法:一种三阶段查询数据增强技术,能使用开源 LLM 来从字幕描述数据集提取指令微调数据。
图2给出的结果凸显了这个框架的多功能性。定量分析表明,X-InstructBLIP 的表现与现有的单模态模型相当,并且能在跨模态任务上表现出涌现能力。而为了量化和检验这种涌现能力,该团队又构建了 DisCRn。这是一个自动收集和调整的判别式跨模态推理挑战数据集,其需要模型分辨不同的模态组合,比如「音频 - 视频」和「3D - 图像」。

方法
图1展示了该模型架构的总体概况:其扩展了 Dai et al. 在 InstructBLIP 项目中提出的指令感知型投影方法,通过独立微调具体模态的 Q-Former 到一个冻结 LLM 的映射,使其可用于任意数量的模态。

图3展示了这个模态到 LLM 的对齐过程,其中突出强调了与每个模态相关的所有组件。
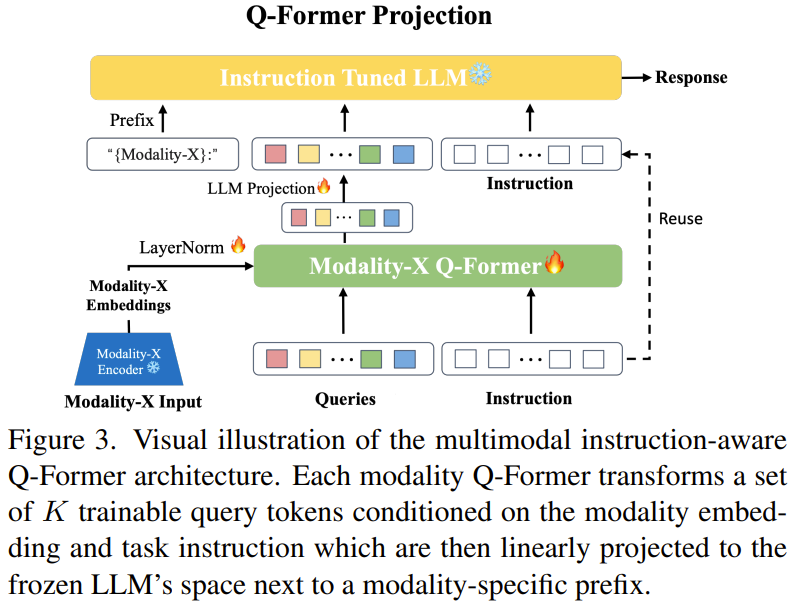
算法1概述了 X-InstructBLIP 对齐框架。

本质上讲,对于每一对文本指令和非语言输入样本:(1) 使用一个冻结的预训练编码器对文本指令进行 token 化,对非文本输入进行嵌入化。(2) 将非语言输入的归一化编码和 token 化的指令输入 Q-Former 模块,并附带上一组可学习的查询嵌入。(3) 通过 Q-Former 对这些查询嵌入进行变换,通过 transformer 模块的交替层中的跨注意力层来条件式地适应这些输入。(4) 通过一个可训练的线性层将修改后的查询嵌入投影到冻结 LLM 的嵌入空间。
数据集
X-InstructBLIP 的优化和评估使用了之前已有的数据集和自动生成的数据集,如图4所示。
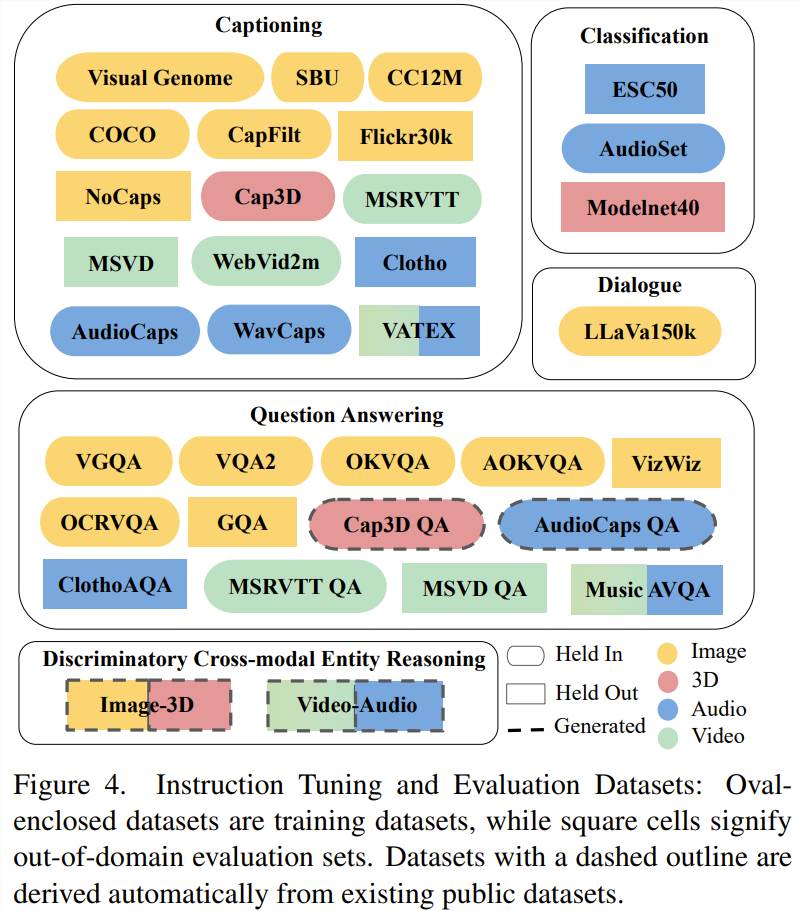
对数据集进行微调
对于已有的数据集,研究者对它们进行了一些微调,详见原论文。
此外,他们还对指令数据进行了增强。由于他们尤其需要3D 和音频模态的数据,于是他们使用开源大型语言模型 google/flan-t5-xxl 基于相应的字幕描述自动生成了3D 和音频模态的问答对。这个过程最终从 Cap3D 的3D 数据得到了大约25万个示例,从 AudioCaps 的音频数据得到了大约2.4万个示例。
判别式跨模态推理
X-InstructBLIP 明显展现出了一个涌现能力:尽管训练是分模态进行的,但它却能跨模态推理。这凸显了该模型的多功能性以及潜在的跨大量模态的可扩展性。为了研究这种跨模态推理能力,该团队构建了一个判别式跨模态推理挑战数据集 DisCRn。
如图5所示,该任务需要模型跨模态分辨两个实体的性质,做法是选出哪个模态满足查询的性质。该任务要求模型不仅能分辨所涉模态的内在特征,而且还要考虑它们在输入中的相对位置。这一策略有助于让模型不再依赖于简单的文本匹配启发式特征、顺序偏差或潜在的欺骗性相关性。

为了生成这个数据集,研究者再次使用了增强指令数据时用过的 google/flan-t5-xxl 模型。
在生成过程中,首先是通过思维链方式为语言模型提供 prompt,从而为每个数据集实例生成一组属性。然后,通过三个上下文示例使用语言模型,使之能利用上下文学习,让每个实例都与数据集中的一个随机实例配对,以构建一个 (问题,答案,解释) 三元组。
在这个数据集创建过程中,一个关键步骤是反复进行的一致性检查:给定字幕说明上,只有当模型对生成问题的预测结果与示例答案匹配时(Levenshtein 距离超过0.9),该示例才会被加入到最终数据集中。
这个优化调整后的数据集包含8802个来自 AudioCaps 验证集的音频 - 视频样本以及来自 Cap3D 的包含5k 点云数据的留存子集的29072个图像 - 点云实例。该数据集中每个实例都组合了两个对应于字幕说明的表征:来自 AudioCaps 的 (音频,视频) 和来自 Cap3D 的 (点云,图像)。
实验
该团队研究了能否将 X-InstructBLIP 有效地用作将跨模态整合进预训练冻结 LLM 的综合解决方案。
实现细节
X-InstructBLIP 的构建使用了 LAVIS 软件库的框架,基于 Vicuna v1.17b 和13b 模型。每个 Q-Former 优化188M 个可训练参数并学习 K=32个隐藏维度大小为768的查询 token。表1列出了用于每种模态的冻结预训练编码器。

优化模型的硬件是8台 A10040GB GPU,使用了 AdamW。
结果
在展示的结果中,加下划线的数值表示领域内的评估结果。粗体数值表示最佳的零样本性能。蓝色数值表示第二好的零样本性能。
对各个模态的理解

该团队在一系列单模态到文本任务上评估了 X-InstructBLIP 的性能,结果展现了其多功能性,即能有效应对实验中的所有四种模态。表2、3、4和6总结了 X-InstructBLIP 在3D、音频、图像和无声视频模态上的领域外性能。




跨模态联合推理

尽管 X-InstructBLIP 的每个模态投影都是分开训练的,但它却展现出了很强的联合模态推理能力。表7展示了 X-InstructBLIP 在视频 (V) 和音频 (A) 上执行联合推理的能力。

值得注意的是,X-InstructBLIP 具备协调统筹输入的能力,因为当同时使用 MusicAVQA 和 VATEX Captioning 中的不同模态作为线索时,模型在使用多模态时的表现胜过使用单模态。但是,这个行为与模型没有前缀提示的模型不一致。
一开始的时候,理论上认为模型没有能力区分对应每种模态的 token,而是将它们看作是连续流。这可能是原因。但是,来自图像 -3D 跨模态推理任务的结果却对这一看法构成了挑战 —— 其中没有前缀的模型超过有前缀的模型10个点。似乎包含线索可能会让模型对特定于模态的信息进行编码,这在联合推理场景中是有益的。
但是,这种针对性的编码并不能让模型识别和处理通常与其它模态相关的特征,而这些特征却是增强对比任务性能所需的。其根本原因是:语言模型已经过调整,就是为了生成与模态相关的输出,这就导致 Q-Former 在训练期间主要接收与特定于模态的生成相关的反馈。这一机制还可以解释模型在单模态任务上出人意料的性能提升。
跨模态判别式推理
该团队使用新提出的 DisCRn 基准评估了 X-InstructBLIP 在不同模态上执行判别式推理的能力。他们将该问题描述成了一个现实的开放式生成问题。在给 LLM 的 prompt 中会加上如下前缀:
在向 X-InstructBLIP (7b) 输入 prompt 时,该团队发现:使用 Q-Former 字幕描述 prompt(这不同于提供给 LLM 模型的比较式 prompt)会导致得到一种更适用于比较任务的更通用的表征,因此他们采用这种方法得到了表8的结果。其原因很可能是微调过程中缺乏比较数据,因为每个模态的 Q-Former 都是分开训练的。
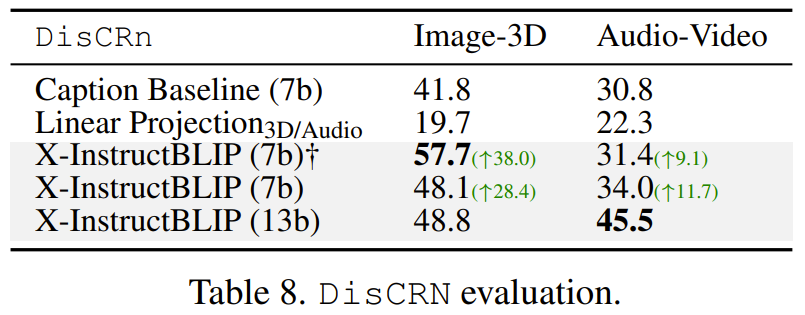
为了对新提出的模型进行基准测试,该团队整合了一个稳健的字幕描述基准,其做法是使用 Vicuna7b 模型用对应于各模态的字幕描述来替换查询输出。对于图像、3D 和视频模态,他们的做法是向 InstructBLIP 输入 prompt 使其描述图像 / 视频,从而得出字幕描述。对于3D 输入,输入给 InstructBLIP 的是其点云的一个随机选取的渲染视图。
结果可以看到,在准确度方面,X-InstructBLIP 分别优于音频 - 视频和图像 -3D 基准模型3.2和7.7个百分点。用等价的线性投影模块替换其中一个 Q-Former 后,图像 -3D 的性能会下降一半以上,音频 - 视频的性能会下降超过10个点。
 相关文章
相关文章
 头条焦点
头条焦点




 精彩导读
精彩导读 关注我们
关注我们
【查看完整讨论话题】 | 【用户登录】 | 【用户注册】