声明:本文来自于微信公众号 机器之心(ID:almosthuman2014),作者:机器之心,授权站长之家转载发布。
在计算机图形学中,「三角形网格」是3D 几何物体的主要表现形式,也是游戏、电影和 VR 界面中主要使用的3D 资产表示方法。业界通常基于三角形网格来模拟复杂物体的表面,如建筑、车辆、动物,常见的几何变换、几何检测、渲染着色等动作,也需要基于三角形网格进行。
与点云或体素等其他3D 形状表示法相比,三角形网格提供了更连贯的表面表示法:更可控、更易操作、更紧凑,可直接用于现代渲染流水线,以更少的基元获得更高的视觉质量。

此前,已有研究者尝试过使用体素、点云和神经场等表示方法生成3D 模型,这些表示也需要通过后处理转换成网格以在下游应用中使用,例如使用 Marching Cubes 算法进行 iso-surfacing 处理。
遗憾的是,这样做的结果是网格密度过高、网格划分过细,经常出现过度平滑和等值曲面化带来的凹凸不平的错误,如下图所示:

相比之下,3D 建模专业人员建模的3D 网格在表示上更加紧凑,同时以更少的三角形保持了清晰的细节。
一直以来,很多研究者都希望解决自动生成三角形网格的任务,以进一步简化制作3D 资产的流程。
在最近的一篇论文中,研究者提出了新的解决方案:MeshGPT,将网格表示直接生成为一组三角形。

论文链接:https://nihalsid.github.io/mesh-gpt/static/MeshGPT.pdf
受语言生成模型 Transformer 的启发,他们采用了一种直接序列生成方法,将三角形网格合成为三角形序列。
按照文本生成的范式,研究者首先学习了三角形词汇,三角形被编码为潜在量化嵌入。为了鼓励学习到的三角形嵌入保持局部几何和拓扑特征,研究者采用了图卷积编码器。然后,这些三角形嵌入由 ResNet 解码器解码,该解码器将其处理表示三角形的 token 序列,生成三角形的顶点坐标。最终,研究者在所学词汇的基础上训练基于 GPT 的架构,从而自动生成代表网格的三角形序列,并获得了边缘清晰、高保真度的优势。
在 ShapeNet 数据集上进行的多个类别的实验表明,与现有技术相比,MeshGPT 显著提高了生成3D 网格的质量,形状覆盖率平均提高了9%,FID 分数提高了30个点。

在社交媒体平台上,MeshGPT 也引发了热议:
有人说:「这才是真正革命性的 idea。」

一位网友指出,该方法的亮点在于克服了其他3D 建模方法的最大障碍,即编辑能力。

有人大胆预测,或许每一个自上世纪90年代以来尚未解决的难题,都可以从 Transformer 中得到启发:

也有从事3D / 电影制作相关行业的用户对自己的职业生涯表示担忧:

不过,也有人指出,从论文给出的生成示例来看,这一方法还未达到大规模落地的阶段,一位专业建模人员完全可以在5分钟内制作出这些网格。

这位评论者表示,下一步可能是由 LLM 控制3D 种子的生成,并将图像模型添加到架构的自回归部分。走到这一步后,游戏等场景的3D 资产制作才能实现大规模的自动化。
接下来,就让我们看看 MeshGPT 这篇论文的研究细节。
方法概述
受大语言模型进步的启发,研究者开发了一种基于序列的方法,将三角形网格作为三角形序列进行自回归生成。这种方法能生成干净、连贯和紧凑的网格,具有边缘锐利和高保真的特点。
研究者首先从大量的3D 物体网格中学习几何词汇的嵌入,从而能够对三角形进行编码和解码。然后,根据学习到的嵌入词库,以自回归下索引预测的方式训练用于网格生成的 Transformer。

为了学习三角形词汇,研究者采用了图形卷积编码器,对网格的三角形及其邻域进行操作,以提取丰富的几何特征,捕捉3D 形状的复杂细节。这些特征通过残差量化被量化为 codebook 中的 Embedding,从而有效减少了网格表示的序列长度。这些内嵌信息在排序后,在重建损失的指导下,由一维 ResNet 进行解码。这一阶段为 Transformer 的后续训练奠定了基础。
然后,研究者利用这些量化的几何嵌入,训练出一个 GPT 类型的纯解码器 transformer。给定从网格三角形中提取的几何嵌入序列,训练 transformer 来预测序列中下一个嵌入的 codebook 索引。
训练完成后,transformer 可以自回归采样,以预测嵌入序列,然后对这些嵌入进行解码,生成新颖多样的网格结构,显示出与人类绘制的网格类似的高效、不规则三角形。


MeshGPT 采用图卷积编码器处理网格面,利用几何邻域信息捕捉表征3D 形状复杂细节的强特征,然后利用残差量化方法将这些特征量化成 codebook 嵌入。与简单的向量量化相比,这种方法能确保更好的重建质量。在重建损失的指导下,MeshGPT 通过 ResNet 对量化后的嵌入进行排序和解码。

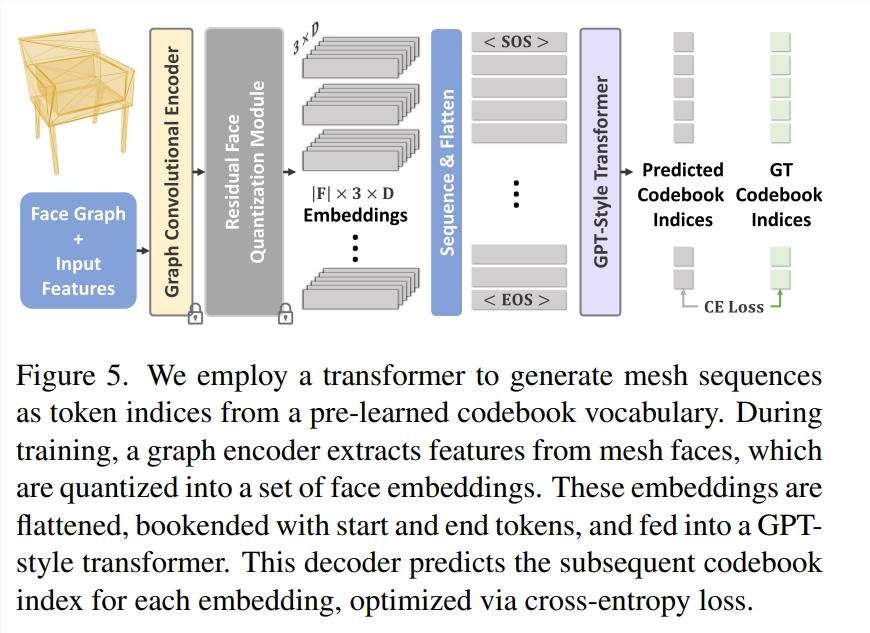
该研究使用 Transformer 从预先学习的 codebook 词汇中生成网格序列作为 token 索引。在训练过程中,图形编码器会从网格面提取特征,并将其量化为一组面嵌入。这些嵌入会被扁平化,用开始和结束 token 进行标记,然后送入上述 GPT 类型的 transformer。该解码器通过交叉熵损失进行优化,预测每个嵌入的后续 codebook 索引。
实验结果
该研究将 MeshGPT 与常见的网格生成方法进行了比较实验,包括:
Polygen,通过首先生成顶点,然后生成以顶点为条件的面来生成多边形网格;
BSPNet,通过凸分解来表征网格;
AtlasNet,将3D 网格表征为多个2D 平面的变形。
此外,该研究还将 MeshGPT 与基于神经场的 SOTA 方法 GET3D 进行了比较。

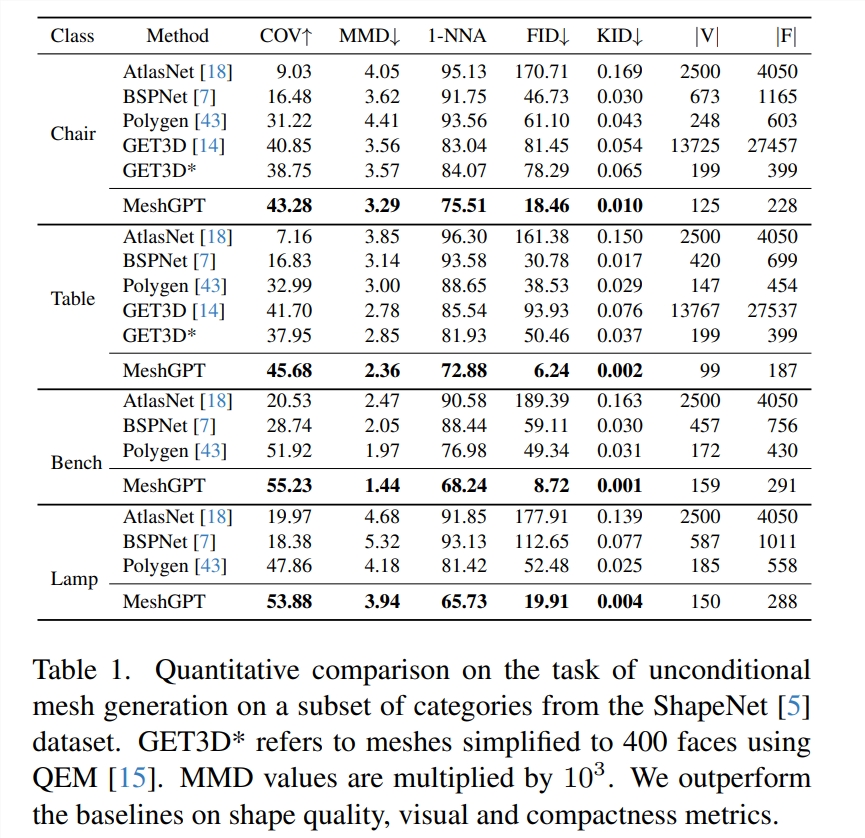
如图6、图7和表1所示,在全部的4个类别中,MeshGPT 都优于基线方法。MeshGPT 可以生成尖锐、紧凑的网格,并具有较精细的几何细节。
具体来说,与 Polygen 相比,MeshGPT 能生成具有更复杂细节的形状,并且 Polygen 在推理过程中更容易积累错误;AtlasNet 经常出现折叠瑕疵(folding artifact),导致多样性和形状质量较低;BSPNet 使用平面的 BSP 树往往会产生具有不寻常三角测量模式的块状形状;GET3D 可生成良好的高层次形状结构,但三角形过多,且平面不完美。


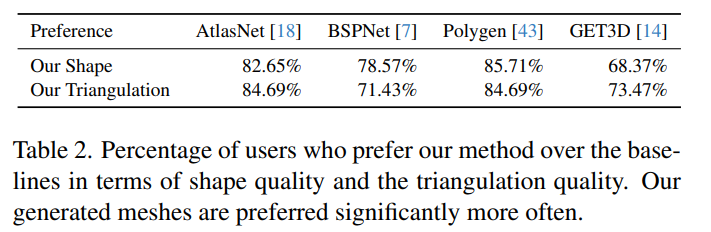
如表2所示,该研究还让用户对 MeshGPT 生成网格的质量进行了评估,在形状和三角测量质量方面,MeshGPT 明显优于 AtlasNet、Polygen 和 BSPNet。与 GET3D 相比,大多数用户更喜欢 MeshGPT 生成的形状质量(68%)和三角测量质量(73%)。
形状新颖性。如下图8所示,MeshGPT 能生成超出训练数据集的新奇形状,确保模型不仅仅是检索现有形状。


形状补全。如下图9所示,MeshGPT 还可以基于给定的局部形状推断出多种可能的补全,生成多种形状假设。

 相关文章
相关文章 头条焦点
头条焦点




 精彩导读
精彩导读 关注我们
关注我们
【查看完整讨论话题】 | 【用户登录】 | 【用户注册】